いよいよRX7900XTと7900XTXのNDAが解禁される日も近づき、ベンチマークのリークなどもチラホラ見られるようになってきました。最近新しいハードウェアを追うのが時間とモチベ的に厳しくなってきているという現実がありますが、いろいろ調べているうちにRDNA3の可能性にワクワクしてきたので、色々な情報の要約や思うことなどをなぐり書きしていこうと思います。
なお、当然リリース前であり、リークデータや予想などを扱っているため、こんな感じになるかもしれないんだな~程度で見ていっていただけると幸いです。
真の競合相手は..4080?
単刀直入に言うと、少なくともRX7900XTXでは4090、ましてや4090Tiに勝てるというのぞみはないと見込まれています。後に詳しく書きますが、無論AMDもRX7900XTXを更にパワーアップしたウルトラハイエンドカードを今後出してきます。ですが、7900XTX/nonXの真の相手はRTX4080であり、リークされたベンチマークもこれを裏付けています。
残念ではありますが、そもそもこのことはだいぶ前から言われていた事でもあり、そこまで驚くべき事実ではないものです。AMDもこれは理解していたことだと思いますし、最初からこのつもりであったと思われます。
とはいえ、AMD側のMSRPはRX7900XTXでも$999。RTX4080のMSRPが$1,199ということを考えると、NVIDIAは大幅な値下げを考えざるを得ない状況になります。ウルトラハイエンドとまではいかなくとも、ハイエンド帯の値下げ、これが今、RDNA3から我々コンシューマーとして受ける一番大きな恩恵です。
RTX4080とくらべて8GBも多くバス幅も広いVRAM、ほぼ同レベルかそれ以上のGPUパフォーマンスに加え、従来どおりの8pin電源コネクタや常識的なカードサイズなどを揃えており、それに加えて$200も安いRX7900XTXを選ばないというオプションはないでしょう。
そもそもRTX4080自体、Ampereをとっとと売り払おうとしているNVIDIAの思惑や、競合相手がいないこともあり、非常に微妙な価格設定になっているというのも事実ではあります。NVIDIAも相当な利幅を持っていると思われるため、値下げをすること自体は可能だとは思いますが、NVIDIAが恐れるべきはRX7900XTXではなく、この先来るであろう"RX7950XT(X?)"と、RDNA3のその先、"RDNA4"です。
RDNA3 - 7000番台と、その先にある未来
7900XTXは完全形態ではありません。かなりの伸びしろが残っています。ここがRDNA3の最大の強みと言えるでしょう。
NVIDIAのGPUやIntelのCPU、それに加えてAMDの従来のGPUなど、今までのシリコンは
「モノリシックデザイン」を使って作られてきました。簡単に言うとすべての機能を一個のダイにおさめてしまおうというデザインアプローチです。

それに比べて今回、AMDはRDNA3に「チップレットデザイン」というデザインアプローチを採用しています。

この2枚の例を見比べると分かる通り、上の4080に採用されているGA103は全て一つのダイが乗っかっているだけなのに対し、下のNavi 31には真ん中にGCDと呼ばれる大きなダイが1つ、そしてそれを囲むようにMCDと呼ばれる6つの小さめのダイが置かれています。このデザインこそが、RDNA3の最大の強みなのです。
半導体は、一つの純粋なシリコンの結晶から作られる、シリコンウェハーという円盤に回路を印刷し、切り出して作られます。

{kind=link}
単純そうに聞こえますが、現代の半導体制作のスケールは想像を絶するほど小さく、この非常に繊細な回路を印刷するという過程には様々な困難があります。このような製品が我々一般人でもなんとか買える値段で売られているという現実は本当に奇跡とも言えると思います。
少々脱線しましたが、上に載せたウェハーの画像をご覧いただけると分かる通り、ウェハーは円形ですが、完成品は四角いため、どうしてもエッジ面でロスが発生します。このロスは一つ一つのチップが大きければ大きいほど増えていきます。これがダイを大きくすると、コストが大幅に上がる理由の一つです。
他にも製造過程で発生する不具合などによりイールド(歩留まり)が落ちやすくなったりする、などの理由もありますが、とにかくダイそのものを巨大化するということはとてもコストの掛かることであり、経済的にとても悪いということを理解していただけたらと思います。しかしこれを逆手に取ると、ダイサイズを小さくすればするほど、製造コストは大きく下がる、ということにもなります。
NVIDIAは近年、ダイサイズの大サイズ化(激ウマギャグ)が進みまくっており、何かとネタにされるほどです。参考として1080Tiと、NVIDIA史上最大のダイサイズを誇る3090/Tiを比較してみましょう。1080Tiのダイサイズは471mm²なのに対し、3090/Tiは驚異の628mm²を誇ります。それに比べ、RDNA3の最大サイズであるGCDの面積はたったの306mm²と、3090/Tiの半分以上、更には5年前のGPUより小さくなっています。この一つ一つのダイサイズを小さくできるという技術こそ、チップレットデザインの最大の強みであり、AMDがRyzenで、Intelに打ち勝てた大きな要因の一つでもありす。
このチップレットデザイン、いい事ずくめに聞こえますがちゃんとデメリットもあります。中でも大きなデメリットとして、複数のダイをつなぐための線を引くのが非常に難しく、コストもかさむ上に物理的な距離が発生するため、通信に遅延が生じて性能が下がりやすいことが挙げられます。要するに複数のダイを繋いで一つのように動かす、ということはとても難しく、性能が下がりやすい上にコストが嵩みやすいのです。
しかし複数のダイを結ぶための線がいくら高いとはいえ、巨大なダイを作る、という行為にはかなりの値段がかかります。つまり、ある程度のサイズからは、ダイサイズを上げるよりも、小さいダイを束ねたチップレットデザインのほうが安くなるのです。そして何よりも、チップレットデザインでは、単純にダイサイズを上げたときのような、指数関数的なコストの上がり方が起こりにくい、つまり更に性能を上げたいのであれば、もっと多くのチップを束ねればいい、ということをコストを抑えつつ行えるのです。実際、AMD自身がRyzenやEpycなどでこの方法を取っていますし、AppleもM1 Ultraで似たようなアプローチを行っています。
この章の冒頭で書いた、「完全形態ではなく、かなりの伸びしろが秘められている」というのは、このことなのです。このアプローチがGPUでも成功すれば、性能を上げたければ、更に多くのチップを束ねる、ということができる可能性があるのです。
一方、モノリシックデザインを使っているNVIDIAに残されてる手札は、更に微細なプロセスを使ったり、更にダイサイズを上げたり、消費電力を代償にクロックを伸ばしたりするしかありません。どれも非常にコストがかかる方法です。それに今からチップレットデザインに着手したと仮定した場合でも、少なくとも市場に出せるのは早く見積もっても5年はかかることでしょう。つまり、NVIDIAはすでにチップレットデザインか、同レベルのブレイクスルーを見つけられていない限り、今後AMDに大幅な遅れをとる可能性があるのです。
製造プロセス - 小さけりゃいいってもんでもない
このチップレットデザイン、コスト面の話では、最大のダイサイズを小さくすることでコストが抑えられる、という話をしてきましたが、チップレットデザインのコスト面での強みはこれだけではないのです。
先程あげたNavi 31のダイ画像の説明に、1つのGCD(Graphics Chiplet Die)とそれを囲むように6つのMCD(Memory Chiplet Die)が存在すると説明しました。GCDでは演算を行うためのシェーダーユニットなどが存在し、MCDにはインフィニティーキャッシュなどが収められています。
演算用のGCDとキャッシュ用のMCDとでダイを完全に分けられる、この特性を活かし、GCDは最先端のTSMCの5nmプロセスで製造をし、MCDはTSMCの6nmプロセスで製造を行っています。これはRyzenでのIOダイとCCDで製造プロセスを変えていたのとよく似ています。
MCDの製造プロセスを落とした理由は、ロジックゲートとキャッシュでは、製造プロセスの微細化によるスケーリングの仕方が違うからです。
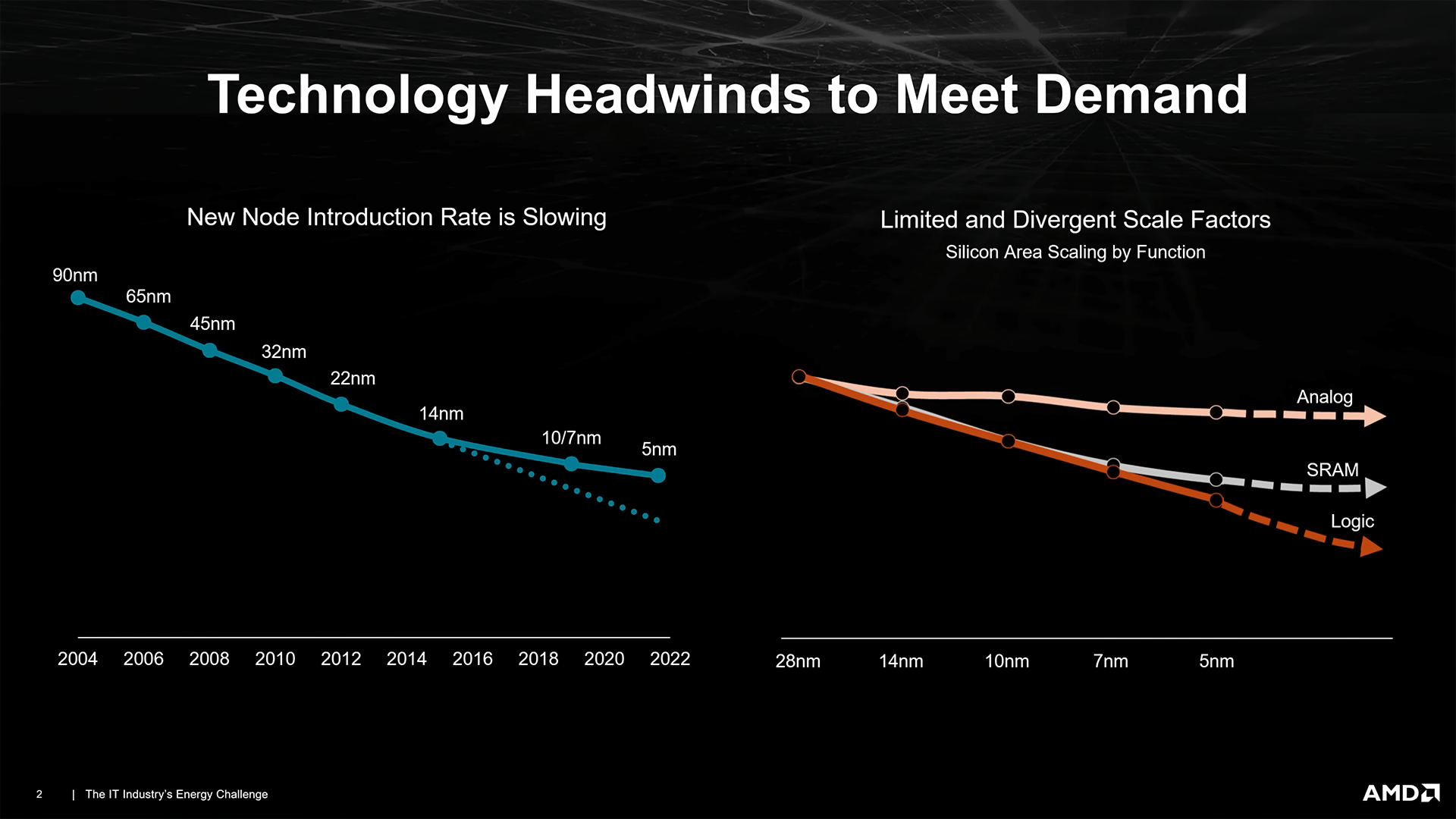
このようにGCDなどで使われるロジックゲートでは、5nmでも順調にスケールしていっていますが、SRAMでは7nmあたりから、アナログ系統では14nmからほぼほぼスケールしていないことがわかります。つまり、これ以上製造プロセスを縮めたとしても、ただただコストが掛かるだけで何もメリットが無いのです。
モノリシックデザインの場合、仮に5nmプロセスで製造を行った場合、このあまりスケールしないキャッシュや配線などにも5nmプロセス分のコストが掛かるのに対し、チップレットデザインではスケールしない部品は古い製造プロセスで作ることができ、製造コストを削減できます。これがチップレットデザインの持つ、隠れた強みでもあるのです。
3Dスタッキング - 同じサイズ、量は倍!
ここまでチップレットデザインに秘められた「伸びしろ」の話をしてきましたが、RDNA3にはもう一つ、大きな「伸びしろ」が存在します。MCDの3Dスタッキングです。
スタッキングとは簡単に説明すると、名前のまんま、2つのチップを重ねて一つのパッケージに納めることです。AMDがR7 5800X3Dでやって一時期ちょっとした話題になっていましたね。あれと似たようなことです。RX7900XTXではスタッキングはされていませんが、このMCDを重ねられるということは、将来的にキャッシュ量を二倍に増やせるポテンシャルが残っているのです。
キャッシュ量を増やすには通常、甚大なコストがかかります。理由は単純、スペースを食うからです。前々の章に書いたとおり、ダイサイズは製造コストに大きく影響します。ダイ内部の地価は非常に高価なので、キャッシュ量を増やすとなると、ダイサイズを上げてコストを上げるか、ダイサイズを維持して演算能力を削らざるを得なくなります。
ところがRDNA3はこの非常にスペースを食うキャッシュを外に追いやり、一個一個のダイをサイズの小さいMCDとすることでコストを下げただけではなく、更にこれを重ねられるというのです。重ねることで、GCDとの物理的な配線距離を短くし、比較的低コストでデータのやり取りにかかる遅延を最小限に留めることができる、というメリットが期待されます。
まとめ
・まずいちばん重要な点として、RX7900XTXの競合相手はRTX4080だということ、そしてRTX4090の競合相手となると予想されるのは、来年出ると予想される"RX7950XT(X?)"ということです。アナウンスメント的にこれがフラッグシップになりそうな雰囲気になっていますが、RX7900XTXはあくまでRTX4080/Tiと同じような立ち位置にあります。
・RDNA3にはまだ伸びしろが残っており、"RX7950XT(X?)"ではNVIDIA以上の追い上げを見せる可能性があります。そしてもし、このアーキテクチャが成功すれば、近いうちにAMDがGPU王者の席に座ることになるのはほぼ確実となります。この「近いうち」が今世代中に来るかどうかは、リサ・スーの握力にかかっています。多分。
・チップレットデザインは、このRDNA3が初めてになるため、まだまだ技術が熟成する可能性も、また秘めていると言って良いと思います。そのため、7000番台が万が一イマイチだったとしても、ただの「成長痛」な可能性もあります。つまり、この技術はRDNA4、更にはその先のアーキテクチャで更に進化を遂げる可能性を秘めているかもしれません。
無論レイトレーシング性能やCUDAなど、NVIDIAには到底及ばない部分も存在し、完璧とは言い難いものの、ゲーム上でのラスター性能という点では、NVIDIAにとっては相当焦るべき存在であると思います。AMD製のCPUとGPUのコンビが、いつかベンチマークのトップに入ることを夢見つつ、NVIDIAにもAMDが独走状態にならないよう、きちんと追従してくれることを願います。
参考サイトなどなど
https://www.youtube.com/@adoredtv
https://www.youtube.com/@MooresLawIsDead